Data Scraping
Knowing more about your business users, industry, and competitors can help you perform better in the market. However, in a world where things change so rapidly, doing so in real-time looks next to impossible. However, not when you do Data scraping. This technique can help businesses and hackers by providing access to readily-available data/information online.
Not sure about what it is and why it might be helpful for you? Read this article to comprehend the essence of web data scraping. This updated guide will help you big time.

Data Scraping Meaning
Every piece of information in the virtual world is data and holds great value. Businesses fetch and keep this data to learn about their customers better, carry out market research, fit product-market fit, create a customer profile, and localize marketing campaigns. As they collect available information, they scrape the web too. That’s what we refer to as data scraping.
If we frame the above information more professionally, it is a data collection approach that involves using automation tools to scrape websites/webpages, open resources, present online, and keep this data in a CSV/Excel file or spreadsheet.
It is not always just businesses that use it. Hackers also use this process to plan an attack. They use the approach to gather email addresses that are later used for phishing scams. Bad actors often access restricted content from a website/webpage using this technique.
On its own, data scraping is 100% legal. But, the intent behind it might cause trouble. This is why many countries have restricted this activity for commercial gains.
Depending upon the type of data pulled, data scraping is divided into three categories that are:
- Report mining involves pulling website data and delivering it into integrated reports.
- Screen scraping, wherein web-scraping tools extra data from legacy systems and migrate it over the updated versions of the OS/device/software.
- Web scraping involves extracting the data, specifically from the website, and delivery to the users via reports so that data is ready for immediate use.
What Are The Dangers of Data Scraping?
Over 4 million personal records were scraped from YouTube alone in 2020. TikTok helped hackers and businesses to extract over 42 million records. These figures are concerning as more data is scraped by powerful hackers.
Other than the increased risk of an attack, data scraping is a huge bolt on a website's terms of privacy. Bots don’t take permission to scrape the data and they often end up extracting confidential details, which doesn't work well for website owners.
When too many bots are accessing a website at the same time, the website server becomes overloaded. They can even put down a server completely, which will make the website inaccessible to legitimate users.
Even if one is scraping websites with good intentions, the growing awareness of user data privacy has made things tough for scraping. If, knowingly or unknowingly, a business extracts mission-critical user data, it can face serious legal implications.
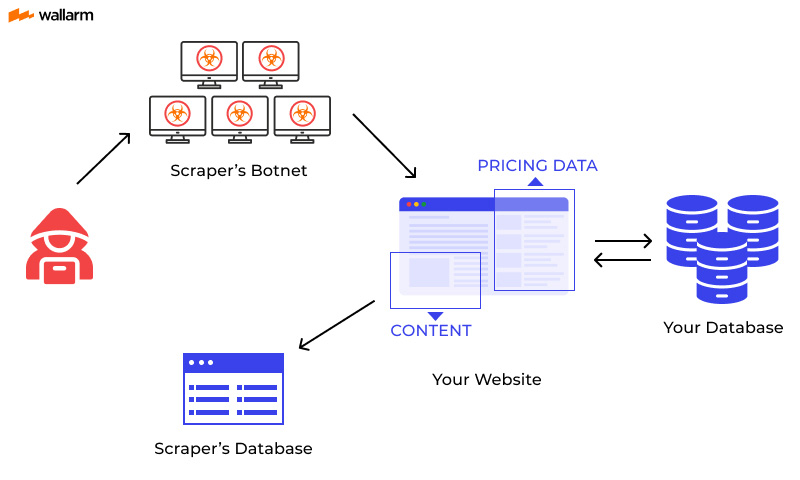
The Bright Side of Using Data Scraping
In a world where data is the Gold, businesses have to have adequate data to support crucial workflows like marketing, CRM, sales, inventory, and so on. Data scraping is a great way to achieve this goal.
It can extract various kinds of data from thousands of websites at a time. As the process is fully automated, one can build a great wealth of data in a short time. Getting started with web scraping is not a very labor and capital-intensive task. One can build a scraper from scratch and start collecting data immediately.
Data Scraping Technology
Data – on the internet and websites – is stored using multiple components and techniques. For instance, a URL defines the location of a website on the internet. Data scraping uses multiple methods wherein different components of a website or internet are scraped to have a hold over the desired dataset. The most commonly used scraping processes are:
- DOM Parsing
DOM declares the content and style of an XML file. It takes a web page as a document and all its content as objects in the document. As the XML file of a website defines how the document is stored and transported, extracting data from the file will help businesses to understand the type of content a website has stored.
DOM parsing technique allows enterprises to scrape data related to the web page structure. Using DOM parsers the right way, it’s easy to figure out nodes and could be a great help to scrape web pages using XPath. These parsers also embed easily in web browsers and can extract full or partial content of a web page.
- HTML Parsing
This one is a very common technique to parse nested or linear HTML pages using JavaScript. HTML parsing is a fast means to collect data stored in links and texts. Also, it can help one scrape screens.
- XPath
Those who need to access the XML document of a website can use the XPath scraping technique, as it can help them to access the tree-like structure of XML documents.
Using the technique, it’s easy to navigate through the XML document and scrape data on multiple parameters. As DOM parsing and XPath are compatible with each other, one can combine them and access detailed data.
- Vertical Aggregation
If an organization is backed by enormous computing resources, it can use it to establish a vertical aggregation platform that will aim at a specific vertical. They are often known as data harvesting resources as they scrape at large. As these are cloud-hosted, easy accessibility and quick actions in scraping are possible.
- Google Sheets
Perhaps the most explicit scraping technique is using Google Sheets. It’s free to use and competent to pull particular websites' data. The in-build function, IMPORTXML, is enough for this task.
How To Mitigate Web Scraping?
The rise of privacy issues and cyberattacks force website owners to execute effective data scraping mitigation policies so that bots can’t steal any necessary data. When implemented correctly, the below-mentioned scraping mitigation strategies will deliver.
Even if bots are smart and gaining new capabilities as days are passing, they can’t beat human intelligence. It does what it’s been told. Throw something in front of a bot that it’s not in its programming, and you will find it inactive.
CAPTCHAs are a great tool to keep scraping bots away from your websites. It’s a challenge-response assessment that will help a website determine whether a human or a bot is accessing it. You can text-based, audio, and video CAPTCHAs on your website. All are equally efficacious.
To gather more and more data from a website, bots make recurring visits, and this is where rate limiting comes in handy. It concerns defining the number of visits a user can make over a website from a specific IP address within a given timeframe.
- Modify HTML markup
Scrapers are designed to understand only one standard website format. Any changes are done in the format, and the data scraping Python bot will skip that website. This is why website owners are recommended not to maintain consistency in the website format.
Altering the HTML markup is an easy way to break the format consistency without causing a huge disturbance in the website's functioning.
- Embedding content into media objects
Even though the approach is not famous, embedding elements into the media objects of a website can stop eCommerce data scraping.
Bots use OCR to extra data from images and media. Adding content into media objects makes their attached string-based text hard to decode for data scraping tools.
Data Scraping vs Data crawling
As accessing data is involved in both these practices, they might sound similar to many. However, they have distinct characteristics. For instance:
Data crawling is used by search engines to find out which content is present and where on which page. This information helps search engineers like Google, Bing Safari, and many more to index a website and its respective page. The crawler just browsers the website pages. There is no data copy-paste going on, which is the case in data scraping.
The purpose of a scraper bot is to collect as much data as possible, while a crawler bot is to visit as many pages as possible.
Scraping involves tricking as bots hide their identity and pretend to be human. Crawler has no intention of fooling the website. The bot reveals its purpose.
Wallarm Will Protect Against Scrape Bots
Businesses, website owners, microservices users, and API consumers can bank upon the advanced API and cloud security services of Wallarm to keep forced scraping at bay. With tools like Cloud WAF (WAAP) and API Security platform, Wallarm empowers websites so much so that they can block malicious codes, enforce rate limiting, and even detect a bot's presence quickly. Start implementing its cutting-edge solution and have ultimate peace of mind.
FAQ
References
Subscribe for the latest news





.jpg)