What is HTTP/2 and how is it different from HTTP/1?
HTTP, HyperText Transfer Protocol, is a synonym to ‘accessing internet’ for most of us. Came into being in 1991, it has been around for quite A long time. The communication protocol – your aid in reaching World Wide Web – needs no introduction today.
While its initial version 1.1 is still the most extensively implemented protocol, it surely has its disadvantages today. That’s what HTTP/2 came into being. This version addresses most of the shortcomings of HTTP v1.1.
In this post, we will define HTTP/2, why it was needed, what are its advantages, why could it be disadvantageous, alongside the key differences between HTTP/2 and HTTP/1.1.


Development Journey: Advancement from HTTP/1 to HTTP/2
In 1989, Tim Berners-Lee invented HTTP. HTTP/1.1 was its 1st standardized version that was available for use in the year 1997 for the end-users. This version presented considerable performance optimization over its precursors and changed how communication was handled between clients and servers. However, its key qualities opened the doors to many performance and API security loopholes.
HTTP/1 was known to have poor response time. With websites becoming more resource-intensive, the protocol was losing its efficiency. It progressively became essential to minimize latency and boost page load speeds.
Google looked into these problems. And as expected, SPDY - an experimental project to end troubles with HTTP/1.x – was put into trial in the year 2010.
Years later, the IETF, Google, Microsoft, and Facebook released the fully-comprehensive and well-tested newer version of HTTP in 2015.
HTTP/2, based on SPDY protocol, was developed to address the inherent limitations of HTTP/1.1 and further progress the Internet.
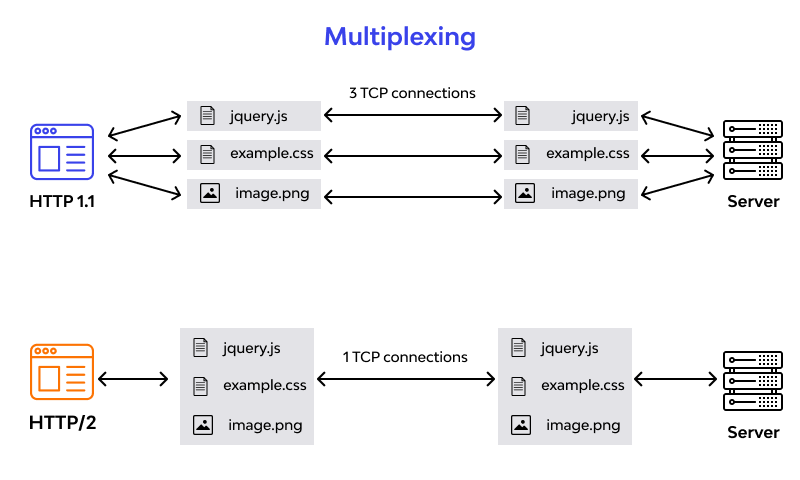
What is the HTTP/2 Protocol
HTTP/2 is the second version of HTTP with most of the shortcomings of its predecessor addressed in it. It has come with advancements in efficiency, speed, and security. Till the date, HTTP/2 is supported on almost all popular web browsers, such as Chrome, Firefox, Internet Explorer, and Safari.
HTTP/2 aims at simplifying, speeding up, and empowering the applications across the internet. To achieve the same, the protocol emphasizes on page load time, resource optimization, and round-trip time (RTT) reduction.
For resource-heavy pages, it supports gradual downloading on the user’s end to improve user experience.
HTTP/1.1 and HTTP/2 Main Differences
Launching of the HTTP/2 was an attempt to overcome the limitations of HTTP/1.1 and make it a more efficient web protocol. So, the major differences in these two are mainly the additions or upgrades applied in HTTP/2. Let’s see what they are:
The Background
For better contextualization of the certain alterations that HTTP/2 made to its precursor, we’ll take a quick look at their basic functionalities and development details first.
HTTP/1.1
HTTP protocol was developed in 1989 as the common language that enables client and server machines’ interaction. Process steps are as enlisted:
- The client (browser) has to send a request to the server using the method (GET/POST).
- Server responds with the requested resource, for example – image, alongside the status of what it did to the client’s request.
Keep in mind that this is not a one-time process. Such requests and responses needs to be transferred between both these machines until the client receives all the resources, essential to load a web page on the end-user’s (your) screen.
This request-response exchange can be regarded as an IP stack being handled by transfer layer and networking layers before finally reaching to the application layer. Now, let’s see how HTTP/2 handles the same scenario.
HTTP/2
HTTP/2 was released at Google as the significant improvement of its predecessor. It was initially modeled after the SPDY protocol and went through significant changes to include features like multiplexing, header compression, and stream prioritization to minimize page load latency. After its release, Google announced that it would not provide support for SPDY in favor of HTTP/2.
The major feature that differentiates HTTP/2 from HTTP/1.1 is the binary framing layer. Unlike HTTP/1.1, HTTP/2 uses a binary framing layer. This layer encapsulates messages – converted to its binary equivalent – while making sure that its HTTP semantics (method details, header information, etc.) remain untamed. This feature of HTTP/2 enables gRPC to use lesser resources.
Delivery Models
As discussed before, HTTP/1.1 sends messages as plain text, and HTTP/2 encodes them into binary data and arranges them carefully. This implies that HTTP/2 can have various delivery models.
Most of the time, a client's initial response in return for an HTTP GET request is not the fully-loaded page. Fetching additional resources from the server requires that the client send repeated requests, break or form the TCP connection repeatedly for them.
As you can conclude already, this process will consume lots of resources and time.
HTTP/1.1
HTTP/1.1 addresses this problem by creating a persistent connection between server and client. Until explicitly closed, this connection will remain open. So, the client can use one TCP connection throughout the communication sans interrupting it again and again.
This approach surely ensures good performance, but it also is problematic.
For example – If a request at the queue head cannot retrieve its required resources, it can block all requests behind it. This phenomenon is called head-of-line blocking (HOL blocking).
From the above, we can conclude that multiple TCP connections are essential.
HTTP/2
Considering the bottleneck in the previous scenario, the HTTP/2 developers introduced a binary framing layer. This layer partitions requests and responses in tiny data packets and encodes them. Due to this, multiple requests and responses become able to run parallelly with HTTP/2 and chances of HOL blocking are bleak.
Not only has it solved the HOL blocking problem in HTTP/1.1, but it also concurrent message exchange between the client and the server. This way, both of them can have more control while the connection management quality is boosted too.
The problems of HTTP/1.1 looks resolved to a great extent here. However, at times, multiple data streams demanding the same resource can hinder HTTP/2’s performance. To achieve better performance, HTTP/2 has another way. It has the capability of stream prioritization.
When sending streams in parallel, the client can assign weights (1-256) to its stream to prioritize the responses it demands. Here, the higher the weight, the higher the priority. The serve sets the data retrieval order as per the request’s weight. Programmers can enjoy better control on page rendering process with stream prioritization ability.

Predicting Resource Requests
As already discussed, the client receives an HTML page on sending a GET request. While examining the page contents, the client determines that it needs additional resources for rendering the page and makes further requests to fetch these resources. As a consequence of these requests, the connection load time increases. Since the server already knows that the client needs additional files, it can save the client time by sending these resources before requesting; thus, offering a great solution to the problem.
HTTP/1.1
To accomplish this, HTTP/1.1 has a different technique called resource inlining, wherein the server includes the required source within the HTML page in response to the initial GET request. Though this technique reduces the number of requests that the client must send, the larger, non-text format files increase the size of the page.
As a result, the connection speed decreases, and the primary benefit obtained from it also nullifies. Another drawback is the client cannot separate the inlined resources from the HTML page. For this, a deeper level of control is required for connection optimization – a need that HTTP/2 meets with server push.
HTTP/2
As HTTP/2 supports multiple simultaneous responses to the client’s initial GET request, the server provides the required resource along with the requested HTML page. This is called the server push process, which performs the resource inlining like its precursor while keeping the page and the pushed resource separate. This process fixes the main drawback of resource inlining by enabling the client machine to decide to cache/decline the pushed resource separate from the HTML page.
Buffer Overflow
Server and client machine TCP connection requires both of these to have a certain buffer space for holding incoming requests.
Though these buffers can hold numerous or large requests, they may also lack space due to small or limited buffer size. It causes buffer overflow at receiver’s end, resulting in data packet loss. For example, packets received after the buffer is full, will be lost.
To prevent it from happening, a flow control mechanism stops the sender from transmitting an overwhelming amount of data to the receiver side.
***
HTTP/1.1
The flow control mechanism in HTTP/1.1 relies on the basic TCP connection. In beginning itself, both the machines set their buffer sizes automatically. If the receiver’s buffer is full, it shares the receive window details, telling how much available space is left. The receiver acknowledges the same and sends an opening signal.
Note that flow control can only be implemented on either end of the connection. Moreover, since HTTP/1.1 uses a TCP connection, each connection demands an individual flow control mechanism.
HTTP/2
It multiplexes data streams utilizing the same (one) TCP connection. So, in this case, both machines can implement their flow controls instead of using the transport layer. The application layer shares the available buffer size data, after which, both machines set their receive window details on the multiplexed streams level. In addition, the flow control mechanism does not need to wait for the signal to reach its destination before modifying the receive window.
Compression
Every HTTP transfer contains headers that describe the sent resource and its properties. This metadata can add up to 1KB or more of overhead per transfer, impacting the overall performance. For minimizing this overhead and boosting performance, compressions algorithms must be used to reduce the size of HTTP messages that travels between the machines.
HTTP/1.1
HTTP/1.x uses formats like gzip to compress the data transferred in the messages. However, the header component of the message is always sent as plain text. Though the header itself is small, it gets larger due to the use of cookies or an increased number of requests.
HTTP/2
To deal with this bottleneck, HTTP/2 uses HPACK compression to decrease the average size of the header. This compression program encodes the header metadata using Huffman coding, which significantly reduces its size as a result. In addition, HPACK keeps track of previously transferred header values and further compresses them as per a dynamically modified index shared between client and server.
Request #1
Request #2
Aside from the path field, all other fields in these requests have the same values. So, when sending the second request, the client machine can use the HPACK format to transfer only the indexed values required to regenerate the common fields and encode the path field in a new manner. The resulting header frames for both requests will look as follows:
HEADERS Frame for Request #1
Advantages and Disadvantages of HTTP/2
Naturally, as the updated technology, HTTP/2 brings its fair share of benefits and drawbacks to the cyber world. Below is the list of the advantages and disadvantages of HTTP/2:
Advantages:
- HTTP/2 supports full multiplexing for requests as well as responses over a single TCP connection. Due to these capabilities, lower page load times are achieved by removing needless latency and improving the overall capacity of network alongside its availability.
- Resource usage has increased dramatically for machines processing requests to deliver media-rich content and complex web designs. Developers worked hard around optimization hacks, and as a result, the robust solution of HTTP/2 was obtained. Features, such as server push, stream dependency and prioritizing, header compression, and binary format layer, have improved network utilization as the core advantage.
- The HTTP/2’s ability to transmit more data per client-server communication cycle greatly improves web performance. As a result, increased user satisfaction, better SEO, greater productivity, growing userbase, and improved sales figures can be achieved.
- All modern browsers support HTTP/2 over HTTPS with the SSL certificate installation. To open HTTPS capable invisible proxy ports on every relevant port, OWASP ZAP or its alternatives could be used.
- The use of the HPACK algorithm enables HTTP/2 to overcome the common API security threats. This protocol has commands in binary format and compresses the HTTP header metadata to protect sensitive data shared between both machines.
Disadvantages:
- While HTTP/2 mitigated the effects of HOL blocking in its predecessor, TCP-level block still causes problems.
- For client machines operating on a slow network, data packets drop bit by bit, and the network quality gets degraded to a single HTTP/2 connection. Due to this, the entire process slows down, thereby blocking a lot of data transfer.
- The cookie security failure is still not addressed in HTTP/2 like its precursor. Cookies are .txt files containing client data obtained by the server and website. However, these cookies may get stolen or tampered with by hackers, who can access personal user data, even without passwords.
What is HTTP/3?
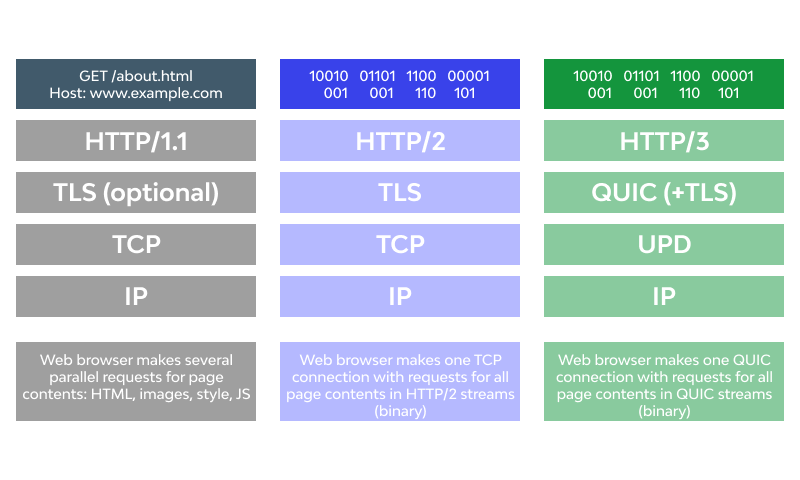
HTTP/3 protocol is the latest version of HTTP that will impact the communication between clients and servers, with significant upgrades for user experience, including API security, reliability, and performance. While the HTTP semantics are consistent across all versions, HTTP/3 differs from its precursors due to the mapping of these semantics to underlying transports.
Both HTTP/1.1 and HTTP/2 use TCP as their transport, whereas HTTP/3 is based on Google’s QUIC – a transport layer network protocol that implements user space congestion control over UDP (User Datagram Protocol).
It has come with many solutions, such as decreased effects of packet loss, zero round-trip time, more comprehensive encryption, and faster connection establishment, to fix HTTP/2’s shortcomings. HTTP/3 will soon be the standard protocol and has already seen a huge roll in libraries, infrastructures, and browsers.
Conclusion
The influence and control of HTTP/2 in the cyber world are absolutely inexorable. The core features of HTTP/2 provide greater levels of control that can be used to optimize the web application performance. Certainly, the tech world is rapidly evolving with each passing year, which needs advanced technologies every now and then. HTTP/3 is the upcoming internet protocol developed to fix the shortcomings of its predecessor. However, there is so much left to do, and HTTP/2 is not going away any time soon.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")